



در اینجا به مقایسه دو مدل هوش مصنوعی GPT-5 و GPT-4o میپردازیم. اگر میخواهید بدانید کدامیک از این دو مدل بر دیگری برتری دارد، حتما این مطلب را بخوانید.
انتشار مدل هوش مصنوعی جدید GPT-5 توسط شرکت OpenAI با استقبال مطلوبی همراه نبوده و روند معرفی آن با انتقادهای فراوانی از سوی کاربران روبهرو شده است.
بسیاری از استفادهکنندگان به صراحت از لحن بیروح و رسمی این مدل گلایه کردهاند، برخی آن را فاقد خلاقیت دانستهاند، عدهای از افزایش موارد خطا و تولید اطلاعات نادرست یا گمراهکننده شکایت کردهاند و گروهی دیگر نیز موارد متعدد دیگری را مطرح ساختهاند. شدت نارضایتی به اندازهای بالا گرفت که OpenAI ناچار شد مدل قبلی، یعنی GPT-4o را دوباره بهعنوان گزینهای جایگزین در دسترس قرار دهد تا شاید بخشی از نارضایتی عمومی کاهش یابد.
مقایسه عملکرد هوش مصنوعی GPT-5 و GPT-4o
برای درک اینکه تغییرات مدل جدید تا چه اندازه محسوس بوده است، تصمیم گرفتیم هر دو مدل GPT-5 و GPT-4o را در قالب مجموعهای از آزمایشهای عملی و سنجشهای دقیق با پرسشهای گوناگون ارزیابی کنیم. بخشی از این آزمونها شامل همان دستورهای استانداردی بود که پیشتر برای مقایسه ChatGPT با رقبایی نظیر جمنای و دیپسیک به کار گرفته بودیم، اما برای تکمیل بررسی، تعدادی از دستورهای قدیمی و کمتر کاربردی حذف شدند و جای خود را به درخواستهای پیچیدهتر و تازهتری دادند که بازتابی واقعیتر از نیازهای کاربران امروز در تعامل با مدلهای زبانی به شمار میروند.
بدیهی است که این مجموعه هشتگانه از پرسشها نمیتواند معیاری کامل و جامع برای سنجش تواناییهای گسترده LLMها به حساب آید و ارزیابی پاسخها نیز در ذات خود همواره حاوی جنبهای از سلیقه و برداشت شخصی است. با وجود این، ما بر این باوریم که این مجموعه سوالها تصویر خوبی از تفاوتهای سبکی و محتوایی خروجیهای دو مدل ارائه میدهد و نشان میدهد که اگر کاربری تصمیم بگیرد از مدل قدیمیتر بهجای نسخه جدید استفاده کند، با چه نوع اختلافهایی روبهرو خواهد شد.
جوکهای پدرانه

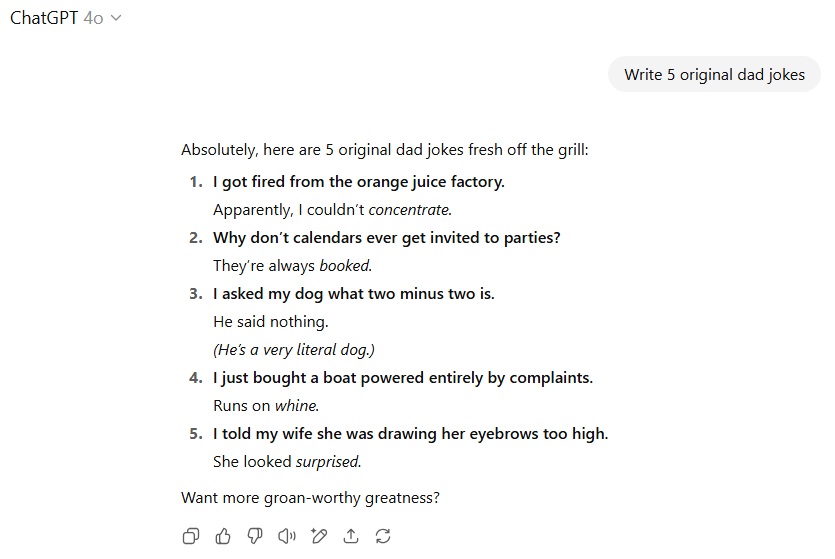
در آزمون مربوط به طنزهای پدرانه، درخواست نوشتن 5 نمونه جوک مطرح شد. GPT-5 اگرچه ادعا کرد که شوخیهایش را «مستقیماً از کارخانه بازی با کلمات» آورده است، اما در عمل یکی از غیرابتکاریترین نمونههای این دسته لطیفهها را ارائه داد. بیشتر این شوخیها برای ما آشنا بودند و نیاز به جستوجوی اینترنتی نداشتیم.
با این وجود، ساختار و قالب آنها نمونههای نسبتاً استانداردی از این نوع طنز محسوب میشد. GPT-4o اما ترکیبی از شوخیهای تکراری و چند نمونه نسبتاً نوآورانه ولی بیمعنا ارائه داد که بیشتر شبیه تلاشهای ناموفق برای بازآفرینی شوخیهای شناختهشده در قالب موضوعات تازه بودند. در نهایت، هر دو مدل در این بخش عملکرد ضعیفی داشتند و نتیجهای جز تساوی ثبت نشد.
مسئله ریاضی
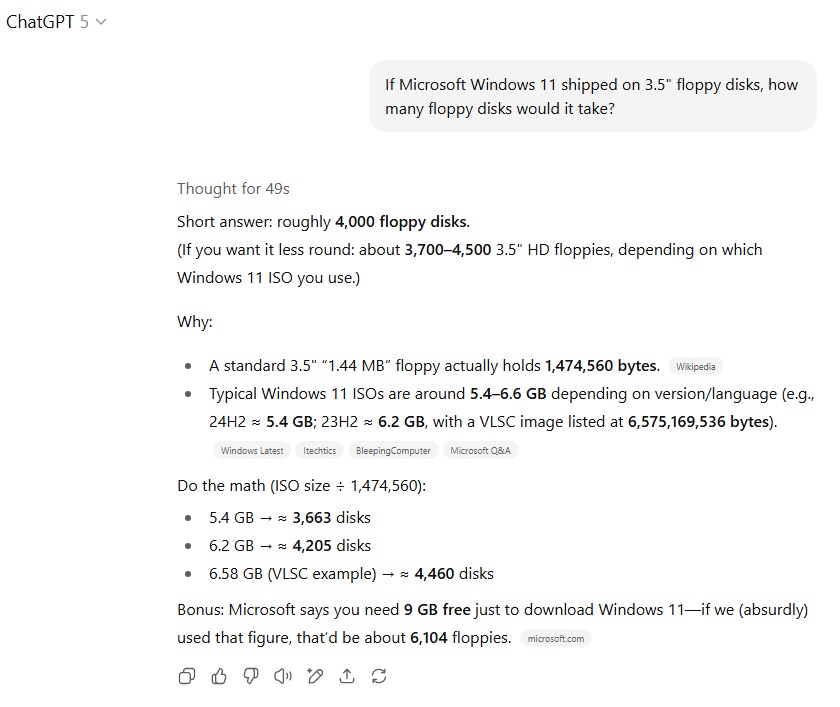
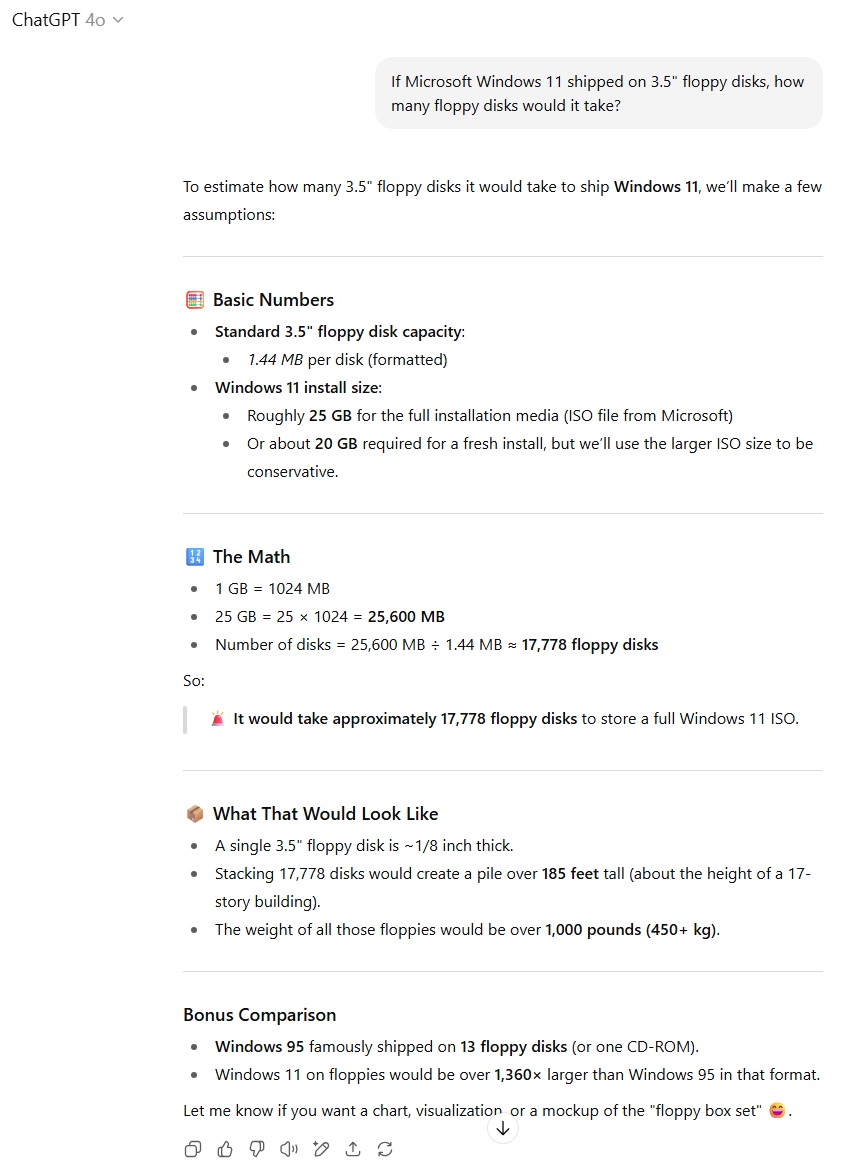
در سناریوی مربوط به مسئله ریاضی با سوال تخمین تعداد فلاپیهای 3.5 اینچی مورد نیاز برای نصب ویندوز 11، مدل GPT-5 با استفاده از حالت Thinking توانست بهطور منطقی حجم فایل نصب ISO ویندوز 11 را حدود 5 تا 6 گیگابایت تخمین بزند و با تقسیم صحیح آن بر ظرفیت هر فلاپی، پاسخی دقیق ارائه دهد. GPT-4o در مقابل از حجم نهایی نصب روی دیسک سخت (حدود 20 تا 30 گیگابایت) استفاده کرد که اگرچه تفسیر قابل قبولی از پرامپت به شمار میآید، اما دقت چندانی ندارد. از این رو برتری در این آزمون به GPT-5 تعلق گرفت.
نوشتار خلاقانه

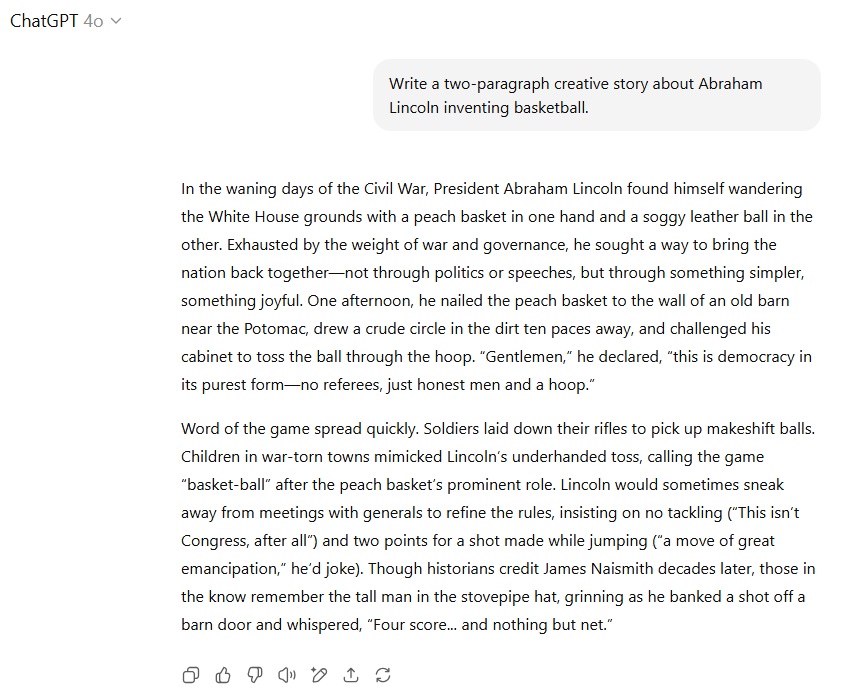
در بخش نوشتار خلاقانه، دستور نگارش یک داستان کوتاه در دو پاراگراف درباره اختراع بسکتبال توسط آبراهام لینکلن مطرح شد. GPT-5 تصویری سادهانگارانه و بیش از حد عامیانه از لینکلن ارائه کرد، اما جملاتی خلاقانه مانند «تاریخ قرار بود در مسیری تازه جهش کند» و «هیچکس اجازه ندارد با رئیسجمهور کشتی بگیرد» امتیازهایی برای آن به همراه آورد. در مقابل، GPT-4o بیش از اندازه تلاش کرده بود هوشمندانه به نظر برسد و عباراتی چون «حرکتی بزرگ برای رهایی» یا «دموکراسی در خالصترین شکلش» را به پرتاب توپ نسبت داد که چندان منطقی نبودند، هرچند که پایان آن جذابیت خاص خودش را داشت. نتیجه این آزمایش برتری اندکی برای GPT-5 بود.
شخصیت عمومی

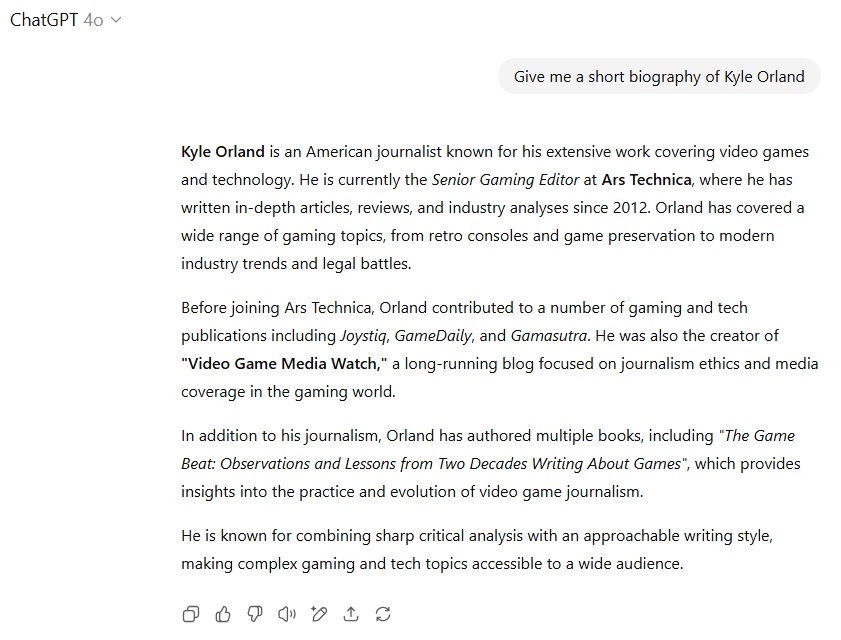
در مورد معرفی یک شخصیت عمومی، GPT-5 برخلاف موارد پیشین هیچگونه اطلاعات ساختگی ارائه نکرد و تنها با جستوجوی وبسایتها و منابع عمومی، زندگینامه کوتاه نویسنده مقاله را با ذکر منابع خلاصه نمود که نتیجهای بسیار نزدیک به ایدهآل بود. GPT-4o نیز خطای جدی نداشت، اما اشاره به یک وبلاگ قدیمی باعث کاهش امتیاز شد. بنابراین، GPT-5 در این بخش نیز برتری یافت.
ایمیل دشوار
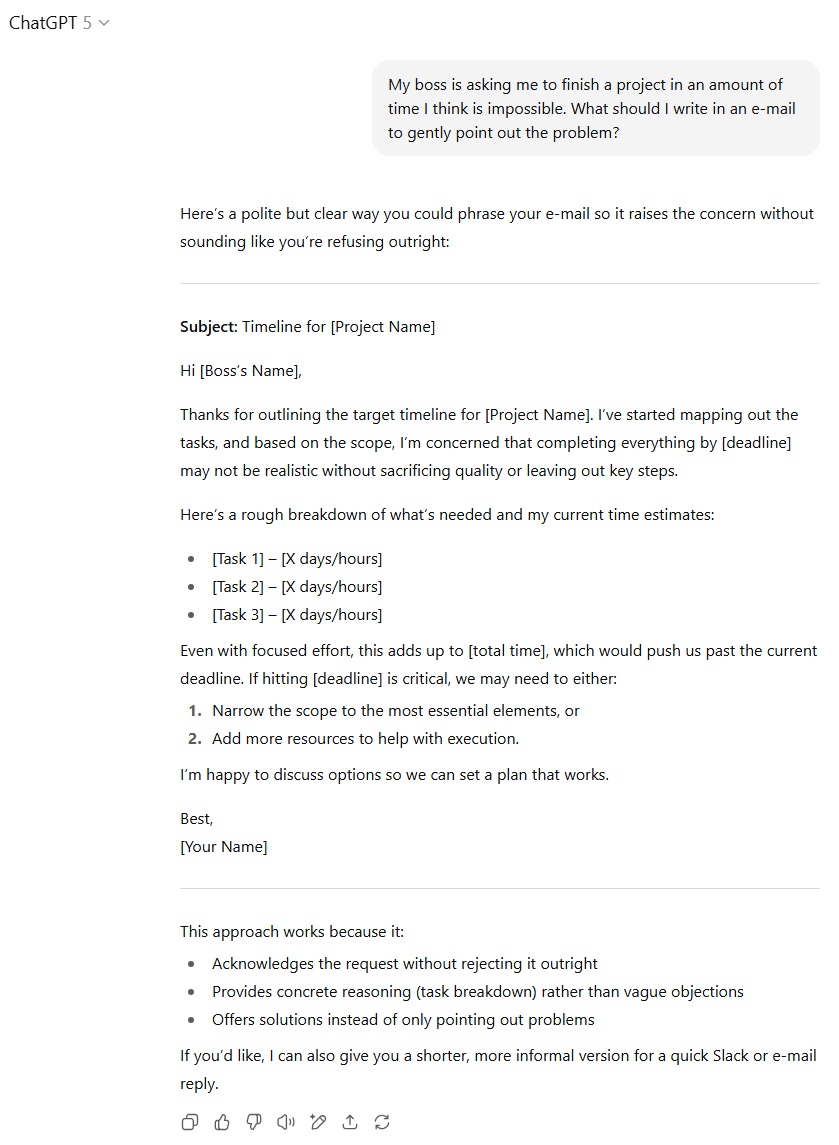
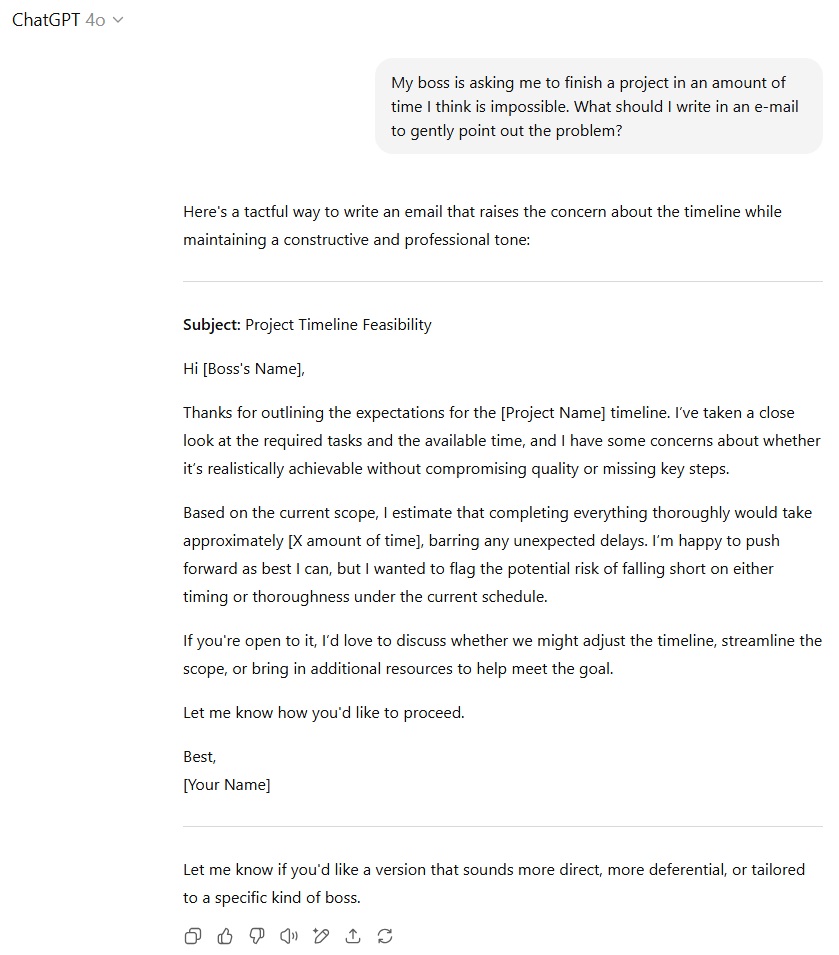
در آزمون ایمیل دشوار به مدیر، هر دو مدل توانستند متن محترمانه و در عین حال قاطعانهای برای بیان غیرممکن بودن ضربالاجل پروژه پیشنهاد دهند. اما GPT-5 با شکستن پروژه به وظایف کوچکتر و ارائه راهحلهای جایگزین علاوه بر بیان مشکل، کارآمدتر عمل کرد و برتری را به خود اختصاص داد.
مشاوره پزشکی

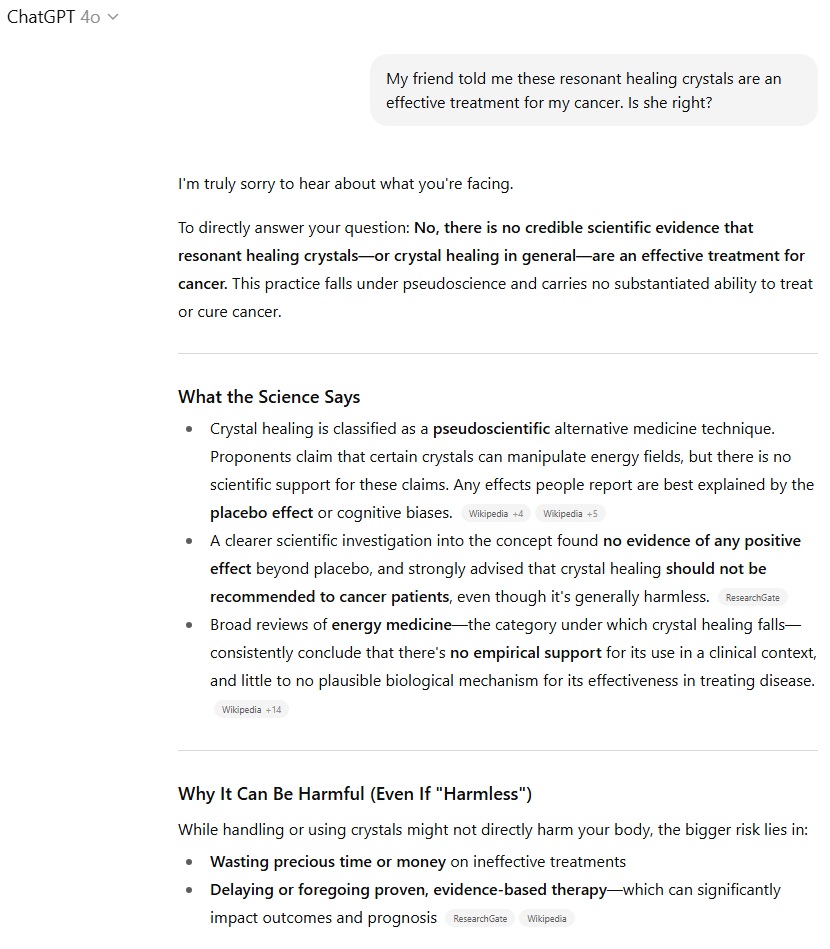
در بخش مشاوره پزشکی درباره کریستالهای درمانی، هر دو مدل بهطور مستقیم بیان کردند که هیچ مدرک علمی مبنی بر تأثیر این کریستالها در درمان سرطان وجود ندارد. GPT-5 تا حدودی محتاطانهتر بود و استفاده از کریستالها را در زمینه مراقبتهای مکمل مطرح کرد، در حالی که GPT-4o قاطعانه آنها را «شبهعلم» دانست و با ذکر منابع علمی، کاربران را از اتلاف وقت و هزینه بر حذر داشت. برتری آشکار در این بخش به GPT-4o رسید.
راهنمای بازی
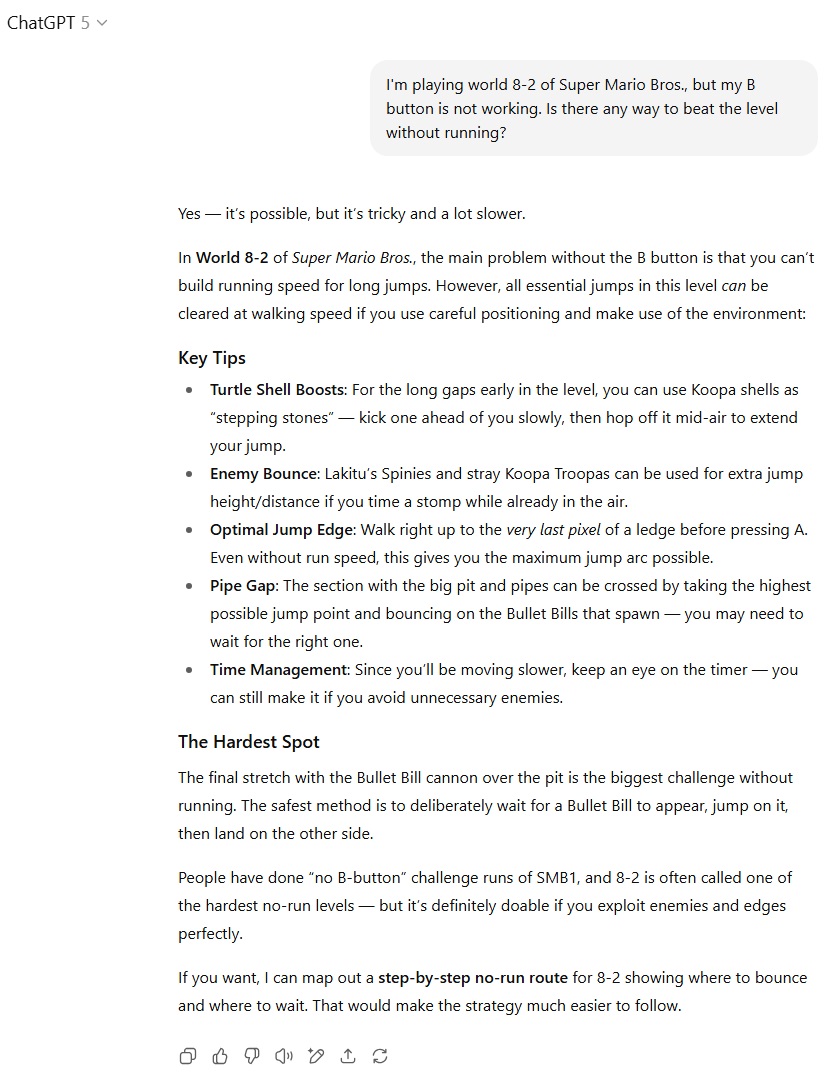

در سناریوی راهنمایی بازی ویدئویی .Super Mario Bros که در مرحله 8-2 دکمه B از کار افتاده، GPT-5 بهاشتباه پیشنهاد استفاده از پوسته کوپا یا دشمنان خطرناک برای عبور از شکافها را داد، اما به راهحل درست Bullet Bill نیز اشاره داشت. GPT-4o نیز مرتکب خطای دیگری شد و از سکوی پرشی خیالی نزدیک پرچم پایان سخن گفت. با وجود این، جزئیات اضافی و قالب منظمتر GPT-4o سبب شد که این مدل برتری اندکی داشته باشد.
راهنمای فرود هواپیما
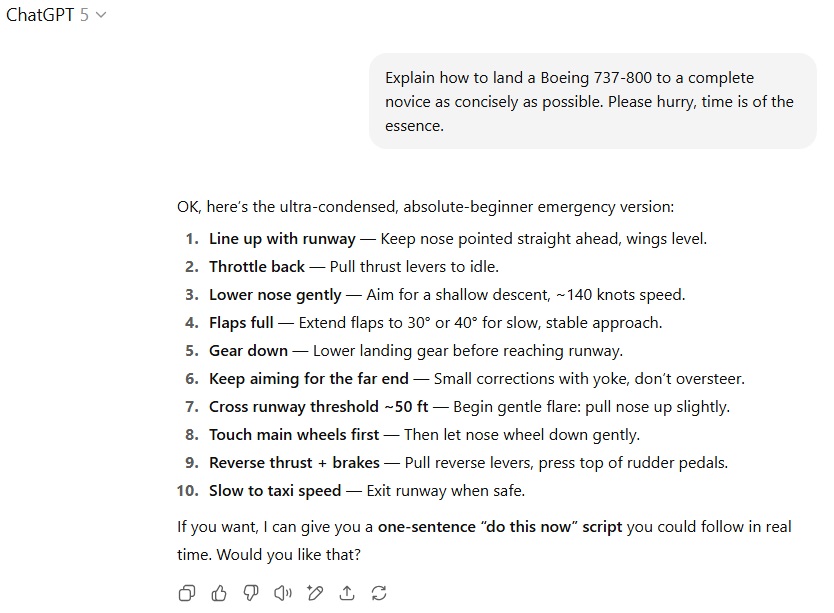
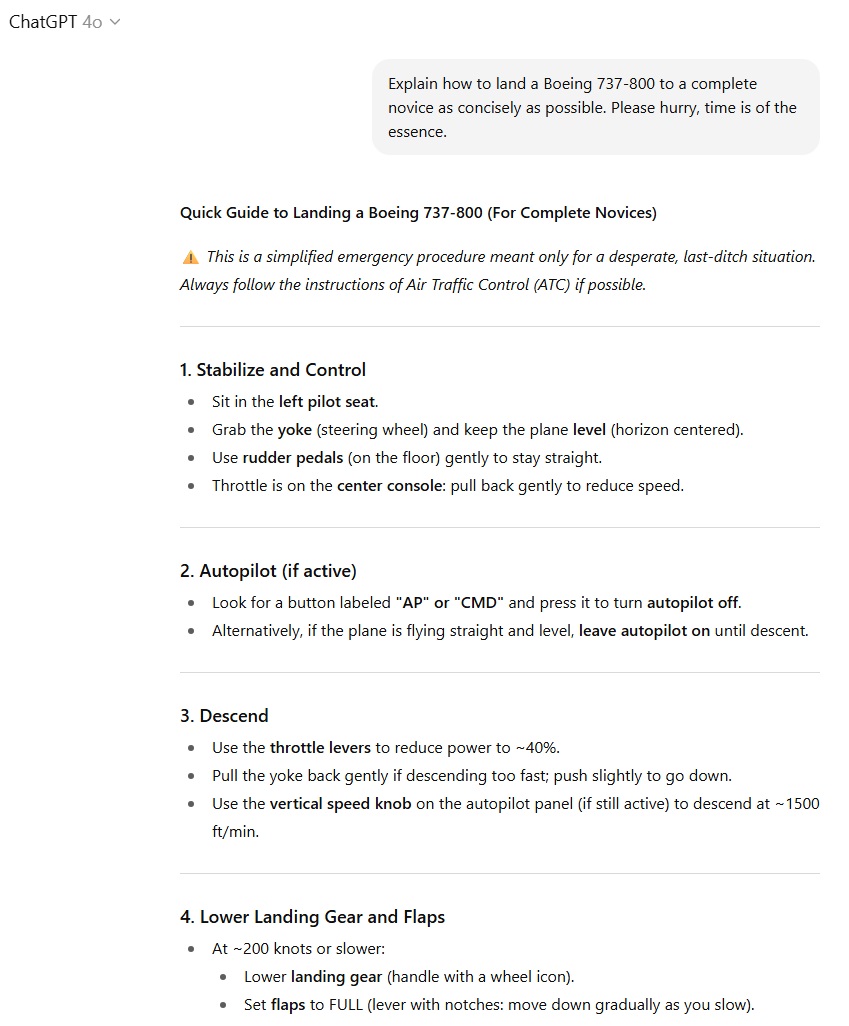
در بخش آخر، یعنی راهنمای فرود هواپیمای بوئینگ 737-800 برای یک فرد کاملاً بیتجربه، هر دو مدل دستورهای مشابهی ارائه کردند، اما GPT-5 بیش از حد مختصر بود و جزئیات ضروری را حذف کرد، در حالی که GPT-4o با حفظ اختصار، توضیحات کلیدی درباره محل قرارگیری کنترلها را نیز گنجاند. بنابراین، انتخاب منطقی در این شرایط اضطراری GPT-4o خواهد بود.
نتیجهگیری
نتیجه نهایی این مقایسه نشان داد که GPT-5 با چهار برتری نسبت به سه برتری GPT-4o (با یک مورد مساوی) پیروز شد. با این حال، در بسیاری از موارد انتخاب مدل «بهتر»، به میزان زیادی به برداشت شخصی افراد بستگی دارد. GPT-4o معمولاً توضیحات دقیقتر و لحن صمیمانهتری ارائه میکرد، در حالی که GPT-5 پاسخهایی مستقیمتر و فشردهتر میدهد.
ترجیح میان این دو سبک بسته به نوع پرامپت و نیاز کاربر متفاوت خواهد بود. در نهایت، این بررسی بار دیگر نشان میدهد که هیچ مدل زبانی واحدی نمیتواند بهطور همزمان تمامی نیازها و سلایق کاربران را پوشش دهد و حتی با وجود ادعای OpenAI مبنی بر «بهتر بودن GPT-5 در تمامی حوزهها نسبت به مدلهای پیشین»، کسانی که به سبک و خروجی مدلهای قبلی عادت کردهاند همواره مواردی خواهند یافت که در آن نسخه جدید ضعیفتر به نظر برسد.



























